
Running LLMs as Easily as Containers
Docker announced a “docker model” feature, available on Docker Desktop 4.40+. This might sound like just another technical update, but it actually represents a new direction in how we can work with AI models in our development workflow. Just as you’d pull and run containers, you can now pull and run AI models with simple commands (docker model <COMMAND>).
From Python Libraries to Docker Containers
Current Approach
I rely heavily on containers for all stages of development (testing, PoCs, MVPs). While I currently use Simon Willison Python LLM project for language model interactions, I’m exploring alternatives.
Potential Benefit
A containerised model approach could potentially replace the Python LLM project once broader GPU support becomes available. The main advantage would be cost efficiency, using the right open source models directly in containers without the additional layer.
Let’s spice things up 🌶️ and enjoy the show that follows…
Why is the Reddit community sceptical?
Because it is Apple Silicon first!
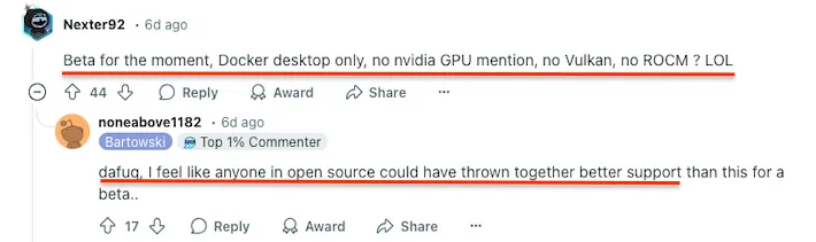
A popular thread on Reddit criticized the initial release being optimized primarily for Apple Silicon. Users with NVIDIA or AMD GPUs felt left out, pointing out that many developers use these platforms for AI work.
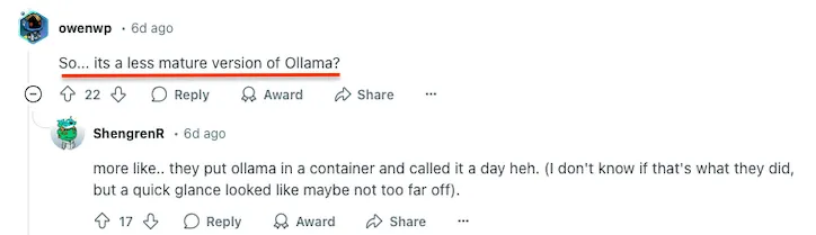
Docker Employer comes to justify Docker’s decisions…
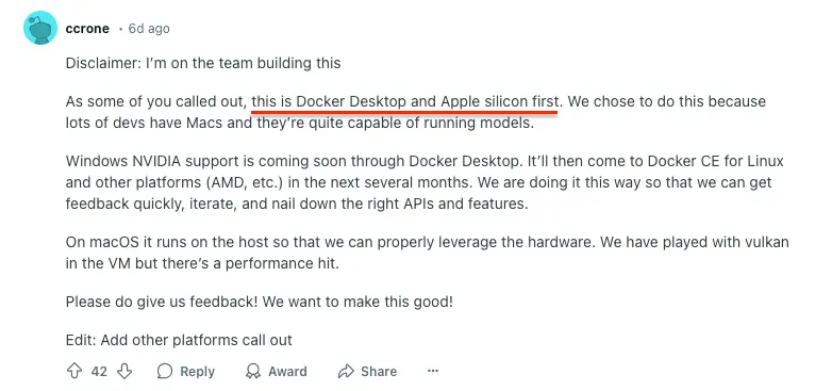
A Docker employee jumped into the thread explaining that Apple Silicon support came first due to “technical priorities” but promised wider GPU support soon. Reddit users weren’t having it.
Reaction…
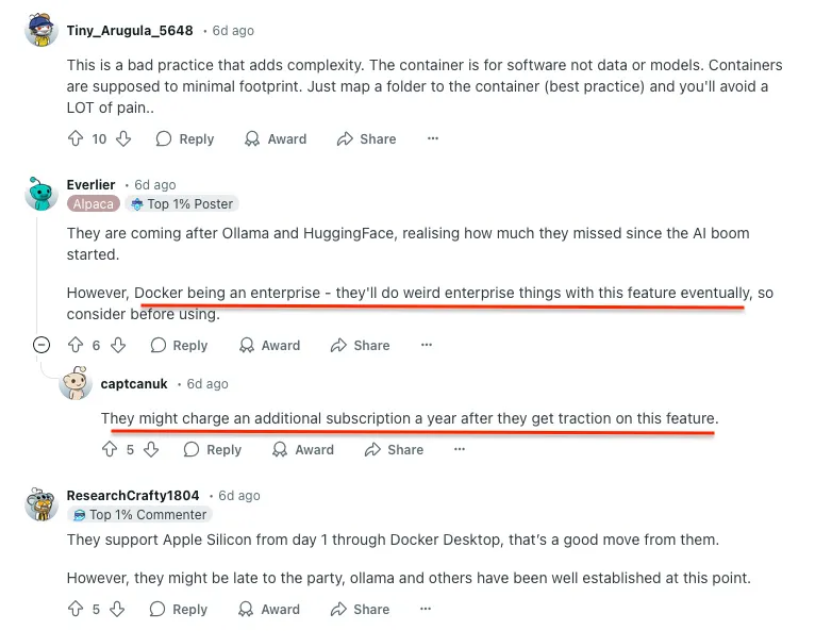
The community response was classic Reddit. Amix of memes, technical critiques, and questions about whether Docker was “pulling an Apple” by creating a walled garden approach.
Enough Drama 🎭 … crack your fingers and hands on your keyboard!
Hint: Don’t forget to update your Docker Desktop to the latest version
Go to Docker hub and find your most suitable model. Personally, I’m using ai/smollm2 for local developement.
Next, use the newly available docker commands…
# pull model
$ docker model pull ai/smollm2
Model ai/smollm2 pulled successfully
# list model
$ docker model list
MODEL PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/smollm2 361.82 M IQ2_XXS/Q4_K_M llama 354bf30d0aa3 3 weeks ago 256.35 MiB
# test newly downloaded model
# Write a python function that calculates the factorial of a number.
$ docker model run ai/smollm2 "Write a python function that calculates the factorial of a number."
def factorial(n):
# Check if input is a non-negative integer
if not isinstance(n, int) or n < 0:
raise ValueError("Input must be a non-negative integer")
# Initialize factorial to 1
result = 1
# Loop from n to 1
for i in range(1, n + 1):
# Multiply with i
result *= i
return result
# Example usage:
print(factorial(5)) # Output: 120
Alternatively, you can use recursion to calculate the factorial:
def factorial(n):
# Base case: factorial of 0 is 1
if n == 0:
return 1
# Recursive case: n! = n * (n-1)!
return n * factorial(n - 1)
# Example usage:
print(factorial(5)) # Output: 120
Verify whether the function correctly calculates the factorial of a number…
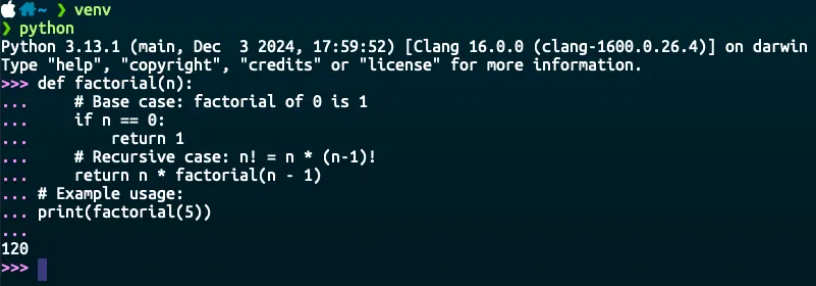
Note: How to calculate the factorial of 5? → 5 x 4 x 3 x 2 x 1 = 120
What next?
Do we actually have valid use cases?
- CI/CD Integration: Add AI checks to your build pipeline for code quality, security scanning, or documentation generation.
- Offline Capabilities: Run your AI-powered tools even when disconnected from the internet. Perfect for when you’re coding in that one coffee shop with terrible Wi-Fi.
- Cost Savings: Avoid API fees for high-volume use cases. Those pennies per request add up quickly when you’re making thousands of calls.
Performance Notes
In my testing, even the small models like smollm2 are surprisingly capable for code generation tasks. The response time varies by complexity, simple prompts finish in 1–3 seconds, while more complex code generation might take 7–15 seconds. Memory usage stays quite reasonable, hovering around 500–800MB during inference. CPU utilization sits around 60–80% during generation but cools down instantly after completion.
Final Thoughts
Is Docker Model Runner ready for production use? Not quite yet. But for experimentation and development workflows, it’s already showing promise. I’ll be watching the GPU support roadmap closely and once it supports more hardware platforms, this could become a standard part of many developers’ toolkits.